There is a common need in Bioinformatics for a local copy of data sets comprising sometimes up to 100,000 remote files each, with various files being retreived from different remote servers. Most bioinformatics scientists write their own Perl / shell / Python or other computer language scripts to download the required remote files to their local computer. Those scripts are usually strongly associated with each particular server and for a specific purpose. It is known that from time to time a connection with a remote server can be arbitrarily dropped, thus interrupting the whole download process. As long as bioinformaticians often download large and numerous data sets, such type of interruption is frequent.
One of the possible solutions is to write an error-proof script that resumes the connection but this would require additional knowledge and developing time from a bioinformatics person. Besides, those scripts are usually written not in a general way and most likely will force the author to do the same job again for a similar task.
Another solution is to use free or commercial download applications. Unfortunately, the user would encounter the same problem, which is that those applications are for general use only and don’t meet all bioinformatics needs. Some of them are designed to enter download settings or copy-and-paste a link of a single file one at a time only, which is not practical for thousands of files. Others allow creating a mirror of the server or making an exact copy of a subset of the whole folders. This would tremendously increase Internet traffic, download time and local storage overhead. There are a few software applications more or less satisfying bioinformatics needs but they are either ftp-server specific or http-server specific, or have some usage limits or much fewer options which are in demand by a bioinformatics user.
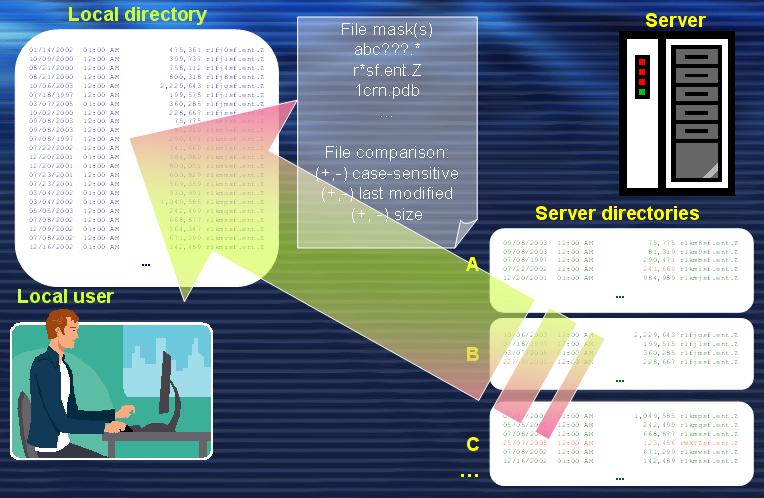
BioDownloader was designed to overcome those problems. It can download large sets of files from remote ftp/http servers to a local computer, and then subsequently update the sets without further user intervention. BioDownloader has a powerful and flexible file selection mechanism. It defines a separate download process as a task. As a result, the user has only the required, most recent server files updated locally for fast access.
It is also known that in Bioinformatics most of the data files need also further processing after being downloaded. Frequently the downloaded files have to undergo archive extracting and/or file copying, and/or moving, and/or renaming. In other cases it is a more complicated user-designed algorithm that has to be applied to each downloaded file. Those algorithms are implemented using different computer language scripts or compiled into independent binary applications.
For that purpose we have developed an automated file processor and included it into BioDownloader. The tool allows to automatically run an external application for each file from a selected set of files. This feature permits to define input arguments (flags and/or parameters) and run the post-download conversion and/or processing of any set of files. Its usage is very simple and flexible, attained by utilizing a very intuitive and convenient graphical user interface (GUI).
Furthermore, all download tasks, task lists, post-download processing/conversion activities can be saved, re-opened, modified, and shared with other users by writing such information into xml-formated files associated with BioDownloader (*.task, *.list, *.convert).